محاسبات هولوگرافیک به استفاده از فناوریهای هولوگرام برای پردازش و تجزیه و تحلیل دادهها در فضای سهبعدی اشاره دارد.





Poison Reverse یکی از تکنیکهای مهم در پروتکلهای مسیریابی Distance-Vector است که برای جلوگیری از ایجاد حلقههای مسیریابی (Routing Loops) و بهبود عملکرد شبکه در پروتکلهایی مانند RIP (Routing Information Protocol) استفاده میشود. این تکنیک بهویژه در شبکههای بزرگ و پیچیدهای که نیاز به مسیریابی دقیق و بهروز دارند، نقش حیاتی دارد. در این مقاله، به بررسی مفهوم Poison Reverse، نحوه عملکرد آن، مزایا و معایب آن خواهیم پرداخت.
Poison Reverse یکی از روشهای مقابله با حلقههای مسیریابی در پروتکلهای مسیریابی Distance-Vector است. در این تکنیک، اطلاعات نادرست مسیریابی که ممکن است باعث ایجاد حلقههای مسیریابی شود، بهطور خاص "مسموم" میشود تا روترها از آنها استفاده نکنند. این تکنیک بهویژه در پروتکل RIP کاربرد دارد و بهطور مؤثر از ایجاد حلقههای مسیریابی جلوگیری میکند.
Poison Reverse یک تکنیک در پروتکلهای مسیریابی Distance-Vector است که به روترها اجازه میدهد تا از ارسال اطلاعات نادرست مسیریابی به همسایگان خود جلوگیری کنند. در این روش، زمانی که یک روتر یک مسیر به مقصد را از همسایه خود دریافت میکند، آن مسیر بهطور معکوس (معمولاً با هزینههای بالا یا به اصطلاح مسموم) به همان همسایه باز میگردد تا از ایجاد حلقههای مسیریابی جلوگیری شود.
به عبارت سادهتر، Poison Reverse به روترها میگوید که اگر مسیری به مقصد از روتر دیگری دریافت شده باشد، همان مسیر را با هزینه بالا (معمولاً با مقدار 16 در پروتکل RIP که نشاندهنده "غیرقابل دسترس بودن" است) به همسایگان خود ارسال کنند. این کار باعث میشود که از ارسال اطلاعات نادرست و بهدنبال آن، ایجاد حلقههای مسیریابی جلوگیری شود.
عملکرد Poison Reverse به این صورت است که هر روتر از آن بهطور خودکار استفاده میکند که اگر مسیری به مقصد از همسایگان خود دریافت کند، آن را با هزینه بسیار بالا (معمولاً 16 برای پروتکل RIP) به همان همسایه باز میگرداند. این کار باعث میشود که همسایهها از مسیر مورد نظر استفاده نکرده و از ایجاد حلقههای مسیریابی جلوگیری شود.
Poison Reverse مزایای زیادی دارد که بهویژه در شبکههای کوچک و متوسط که از پروتکلهای مسیریابی Distance-Vector استفاده میکنند، مفید است. برخی از مزایای آن عبارتند از:
با وجود مزایای زیادی که Poison Reverse دارد، این تکنیک نیز معایب خاص خود را دارد که باید در نظر گرفته شوند. برخی از معایب آن عبارتند از:
Poison Reverse در بسیاری از شبکهها و پروتکلهای مسیریابی Distance-Vector بهویژه در پروتکل RIP کاربرد دارد. برخی از کاربردهای اصلی آن عبارتند از:
Poison Reverse یک تکنیک مؤثر در پروتکلهای مسیریابی Distance-Vector است که برای جلوگیری از حلقههای مسیریابی استفاده میشود. این تکنیک با ارسال مسیرهای مسموم به همسایگان، از ارسال اطلاعات نادرست و بهدنبال آن، ایجاد حلقههای مسیریابی جلوگیری میکند. با این حال، در برخی شرایط خاص، استفاده از Poison Reverse ممکن است محدودیتهایی ایجاد کند. برای درک بهتر نحوه عملکرد Poison Reverse و بهینهسازی مسیریابی در شبکه، میتوانید به سایت saeidsafaei.ir مراجعه کنید.
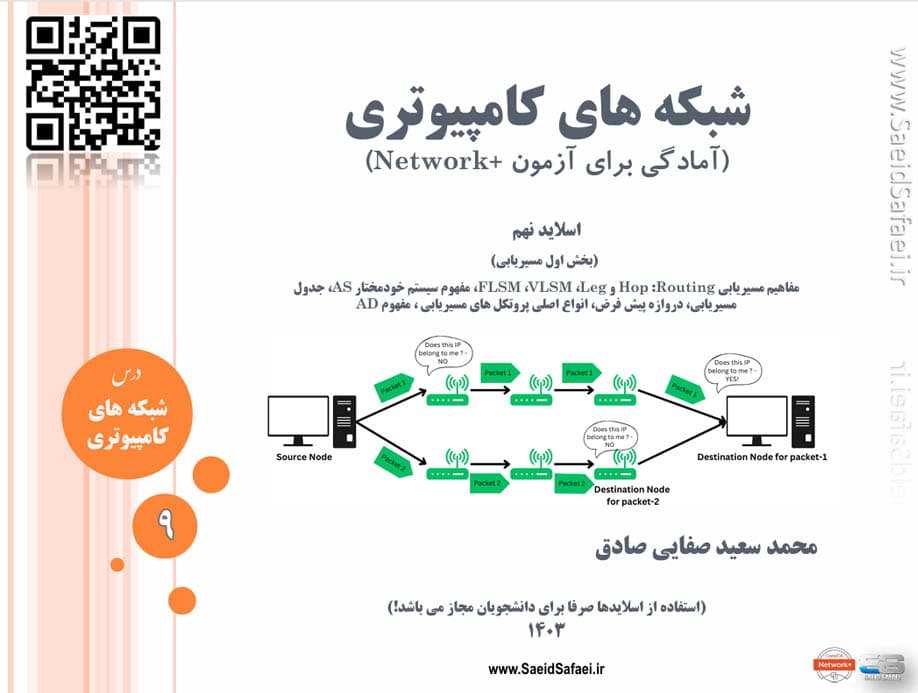
در این جلسه (بخش اول مسیریابی)، مفاهیم پایهای مسیریابی (Routing) مانند Hop، InterVLAN و Leg بررسی میشوند. سپس، تکنیکهای VLSM (Variable Length Subnet Mask) و FLSM (Fixed Length Subnet Mask) توضیح داده میشوند. همچنین، مفهوم سیستم خودمختار (AS) و اهمیت آن در مسیریابی، ساختار جدول مسیریابی و نقش دروازه پیشفرض بررسی خواهد شد. در نهایت، انواع کلاسهای پروتکلهای مسیریابی معرفی و ویژگیهای آنها مورد بحث قرار میگیرد. هدف این جلسه، درک اصول مسیریابی و نحوه مدیریت مسیرها در شبکههای پیچیده است.
محاسبات هولوگرافیک به استفاده از فناوریهای هولوگرام برای پردازش و تجزیه و تحلیل دادهها در فضای سهبعدی اشاره دارد.
هوش مصنوعی مولد به استفاده از الگوریتمهای هوش مصنوعی برای تولید دادهها و محتواهایی مشابه انسان اطلاق میشود.
توابع هش رمزنگاری به توابع ریاضی اطلاق میشود که دادهها را به یک رشته ثابت طول تبدیل میکنند و برای امنیت دادهها استفاده میشوند.
یکپارچگی دادهها به تضمین صحت، دقت و اعتبار دادهها در سراسر سیستمهای مختلف اطلاق میشود.
پروتکل مسیریابی که مسیریابی را بر اساس تعداد هاپها محاسبه میکند و اطلاعات بهصورت دورهای بین روترها ارسال میشود.
تعداد تکرارهای یک موج در یک ثانیه، که معمولاً بر حسب هرتز (Hz) اندازهگیری میشود.
چگونگی چیدمان فیزیکی و منطقی اجزای شبکه که در آن نحوه اتصال گرهها و نحوه انتقال دادهها توصیف میشود.
یک نیبل معادل 4 بیت است و معمولاً برای نمایش یک نیمکلمه در سیستمهای کامپیوتری استفاده میشود.
محاسبات لبه در اینترنت اشیاء به انجام پردازش دادهها در دستگاههای لبه شبکه برای کاهش تأخیر و افزایش سرعت واکنش اطلاق میشود.
نرخ بیت متغیر که در آن نرخ انتقال دادهها بسته به نیاز و پیچیدگی دادهها تغییر میکند.
آزادسازی حافظه به فرآیند آزاد کردن حافظه اختصاصیافته به برنامه یا دادهها پس از پایان استفاده از آنها اطلاق میشود.
کانکتور مخصوص کابلهای تلفن که برای کابلهای UTP CAT-1 استفاده میشود.
آرایه دو بعدی آرایهای است که از سطرها و ستونها تشکیل شده و برای ذخیره دادههایی مانند جدولها استفاده میشود.
ساختارهایی در برنامهنویسی شیگرا هستند که دادهها و متدهای مربوط به آنها را به یک واحد منطقی گروهبندی میکنند.
روندی است که ورودیها را به خروجیها تبدیل میکند. این فرآیند میتواند شامل محاسبات، پردازش دادهها یا انجام کارهای خاص باشد.
اتصال 5G به نسل پنجم ارتباطات بیسیم اشاره دارد که سرعت و ظرفیت شبکه را به طور قابل توجهی افزایش میدهد.
شبکههای هوشمند به سیستمهای برقرسانی گفته میشود که از فناوریهای دیجیتال برای نظارت و بهینهسازی مصرف انرژی استفاده میکنند.
سیستمهای محاسباتی شناختی به استفاده از فناوریها برای شبیهسازی فرایندهای فکری انسانها و انجام تحلیلهای پیچیده اطلاق میشود.
سیستمهای خودترمیمی به سیستمهایی اطلاق میشود که قادر به شناسایی و اصلاح خطاهای خود بدون نیاز به مداخله انسان هستند.
نویز ناشی از سیگنالهای الکتریکی غیرقابل پیشبینی که معمولاً از دستگاههای الکترونیکی و صنعتی تولید میشود.
دروازه منطقی XOR که زمانی خروجی 1 میدهد که ورودیها متفاوت باشند.
قسمت اعشاری یا کسری یک عدد که در سیستمهای عددی به خصوص در مبنای 10 یا 2 نمایش داده میشود.
الگوریتمهای ژنتیک به روشهای محاسباتی اطلاق میشود که از فرآیندهای طبیعی تکامل برای حل مسائل پیچیده استفاده میکنند.
استاندارد شبکههای بیسیم (Wi-Fi) که پروتکلهای ارتباط بیسیم در باندهای مختلف فرکانسی را تعریف میکند.
سیستمهای خودمختار به سیستمهایی اطلاق میشود که قادر به انجام وظایف پیچیده بهطور خودکار و بدون نیاز به نظارت انسان هستند.
متد مشابه به تابع است اما معمولاً در زبانهای شیگرا استفاده میشود و متعلق به یک کلاس خاص است. متدها میتوانند بر روی دادههای شی عمل کنند.
آرایه ایستا، آرایهای است که در آن اندازه از قبل تعریف میشود و نمیتوان در زمان اجرا اندازه آن را تغییر داد.
سیستمهای شناسایی بیومتریک به استفاده از ویژگیهای بیولوژیکی و رفتاری افراد برای شناسایی و تأیید هویت آنها اطلاق میشود.
مدل ارتباطی که در آن هر دستگاه در شبکه بهعنوان همتا عمل میکند و میتواند بهطور مستقیم با دستگاههای دیگر ارتباط برقرار کند.
جدول هش یک ساختار دادهای است که برای ذخیره دادهها بر اساس کلیدها و انجام عملیات جستجو سریع طراحی شده است.
تداخل زمانی رخ میدهد که دو یا چند دستگاه به طور همزمان اقدام به ارسال داده بر روی یک مسیر انتقال مشترک کنند و باعث میشود دادهها با هم ترکیب شوند.
اپلیکیشنهای بومی ابری به برنامههایی اطلاق میشود که به طور ویژه برای محیطهای ابری طراحی شدهاند.
نرمافزارهای کاربردی هستند که برای انجام کارهای خاص مانند پردازش کلمات، تجزیه و تحلیل دادهها و طراحی گرافیکی استفاده میشوند.
پهپادهای خودمختار به وسایل نقلیه هوایی بدون سرنشین اطلاق میشود که قادر به انجام وظایف خودکار مانند نقشهبرداری و نظارت هستند.
علم داده به فرآیندهای تحلیل و تفسیر دادههای پیچیده بهمنظور استخراج الگوهای کاربردی و پیشبینی روندهای آینده اشاره دارد.
